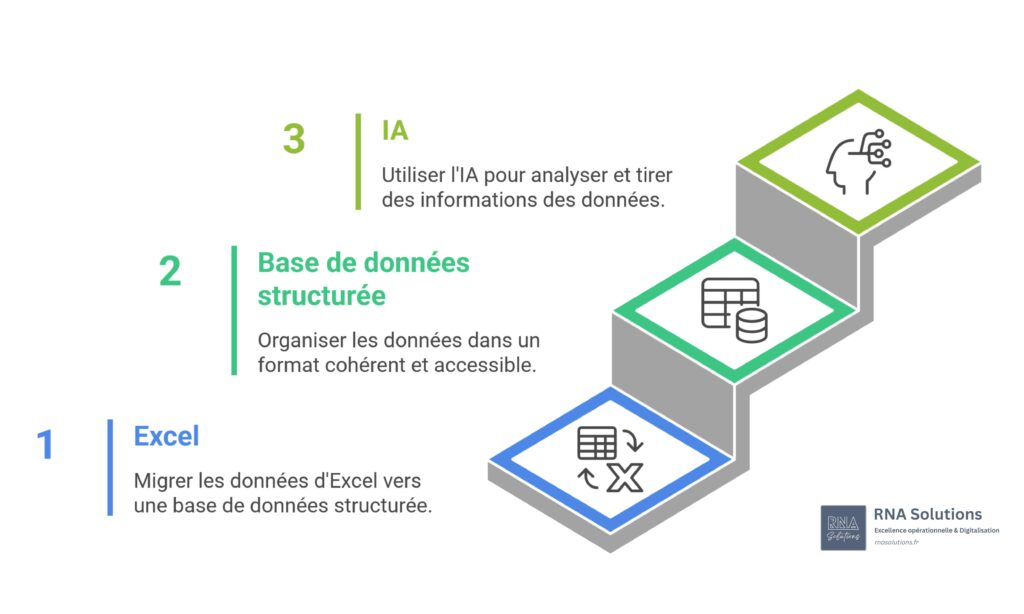
Structurer vos données de production constitue la première étape indispensable avant tout projet d’intelligence artificielle dans votre usine. Sans données propres et centralisées, même les algorithmes les plus performants échoueront.
La réalité dans 78% des PME industrielles françaises ? Des fichiers Excel dispersés entre services, des données de production fragmentées, et une impossibilité d’exploiter l’IA faute d’une base solide. Vos feuilles de calcul contiennent peut-être 10 ans d’historique de production, mais dans leur état actuel, elles ne peuvent pas alimenter une analyse prédictive ou un dashboard temps réel.
Ce guide vous accompagne étape par étape dans la transformation de vos données production : du chaos Excel vers une infrastructure no-code structurée, prête pour l’IA. Vous découvrirez comment nettoyer, centraliser et automatiser vos flux de données sans coder, avec des exemples concrets applicables dès cette semaine dans votre usine.
Ce que vous allez apprendre :
- Les 5 étapes pour nettoyer et structurer vos données existantes
- Comment centraliser vos sources de données dans un outil no-code
- Les erreurs critiques qui condamnent 60% des projets de transformation digitale
- Un plan d’action concret pour préparer vos données aux cas d’usage IA
Pourquoi vos données actuelles ne sont pas prêtes pour l’IA
Le syndrome Excel : diagnostic d’une situation commune
Dans l’immense majorité des PME manufacturières, les données de production vivent dans des dizaines de fichiers Excel dispersés. Le responsable production maintient son tableau de suivi OEE, le chef d’atelier a sa feuille de temps de cycle, la maintenance gère ses interventions dans un autre fichier.
Le problème ? Chaque fichier utilise sa propre structure. Les noms de machines varient (« Presse 1 », « P1 », « Presse_01 »). Les dates suivent des formats différents. Les doublons se multiplient. L’historique se perd quand quelqu’un « nettoie » sa feuille.
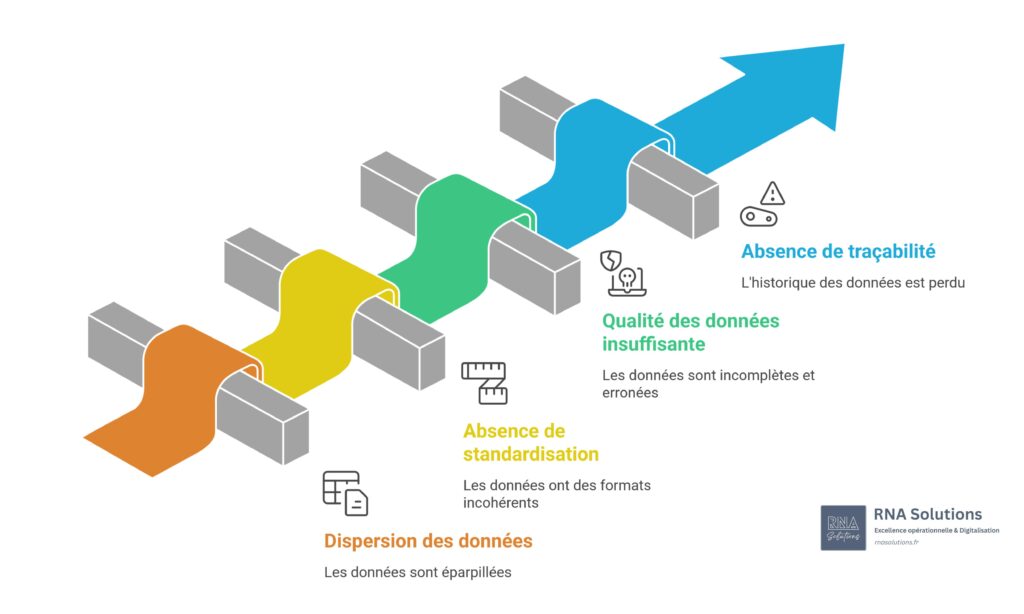
Les 4 obstacles qui bloquent l’exploitation IA
1. Dispersion des sources de données
Vos données de production sont éparpillées entre fichiers locaux, serveurs partagés, emails, et notes papier. Impossible de croiser les informations pour une analyse globale.
2. Absence de standardisation
Même donnée = 5 formats différents. Un taux de rebut s’exprime tantôt en pourcentage (3,2%), tantôt en décimal (0,032), tantôt en pièces (32 rebuts/1000). L’IA ne peut pas apprendre sur des données incohérentes.
3. Qualité de données insuffisante
Cellules vides, valeurs aberrantes (120% de disponibilité ?), unités manquantes, calculs erronés qui se propagent. Selon une étude de 2025, 40% des PME industrielles renoncent à l’IA faute de qualité de données suffisante.
4. Absence de traçabilité et d’historique
Les anciennes versions écrasent les nouvelles. Impossible de retrouver l’état de la production il y a 6 mois. Les décisions se prennent sur des données du moment, sans perspective historique.
Pourquoi le no-code change la donne en 2026
Les outils no-code comme Airtable, Notion ou Baserow permettent de structurer vos données sans compétences techniques tout en offrant les avantages d’une vraie base de données : relations entre tables, validation automatique, historisation des modifications, accès multi-utilisateurs.
Ces plateformes s’intègrent facilement avec des outils d’automatisation (n8n, Make) et des API d’IA, créant un pont naturel entre vos données métier et l’intelligence artificielle. Le coût d’entrée ? Entre 0€ (versions gratuites) et 20€/utilisateur/mois, contre plusieurs dizaines de milliers d’euros pour un MES traditionnel.
La méthodologie de structuration des données en 5 étapes
Étape 1 : Auditer et cartographier vos sources de données actuelles
Objectif : Identifier tous les fichiers, tous les flux, toutes les données de production existantes avant de décider ce qu’on garde et ce qu’on transforme.
Actions concrètes :
1. Recensement exhaustif des fichiers Excel/CSV
Parcourez vos serveurs partagés, postes locaux, boîtes emails. Listez chaque fichier contenant des données de production, qualité, maintenance, ou logistique. Ne négligez pas les fichiers « personnels » de vos chefs d’équipe.
2. Identification des propriétaires et utilisateurs
Pour chaque source : Qui crée les données ? Qui les met à jour ? Qui les consulte ? À quelle fréquence ? Cette cartographie révèle les flux réels, pas ceux décrits dans la documentation officielle.
3. Analyse de la structure et du contenu
Pour vos 5-10 fichiers les plus critiques, documentez : colonnes utilisées, types de données, plages de valeurs, fréquence de mise à jour, historique disponible.
4. Évaluation de la qualité
Calculez pour chaque source : taux de remplissage (% de cellules non vides), cohérence (même format partout ?), fiabilité (les chiffres sont-ils vérifiés ?).
Erreur à éviter : Se limiter aux sources « officielles ». Souvent, les fichiers Excel les plus précieux sont ceux maintenus informellement par un opérateur expérimenté qui compense les lacunes du système officiel.
Conseil pratique : Utilisez un tableau Airtable pour centraliser cet audit. Colonnes suggérées : Nom fichier, Propriétaire, Données contenues, Fréquence MAJ, Qualité (1-5), Priorité (Haute/Moyenne/Basse).
Résultat attendu : Une vision claire de votre patrimoine données actuel, avec 5 à 10 sources prioritaires identifiées pour la transformation.
Étape 2 : Définir votre modèle de données cible
Objectif : Concevoir une structure cohérente qui supportera vos besoins actuels ET vos cas d’usage IA futurs.
Actions concrètes :
1. Identifier vos entités métier principales
Dans une PME industrielle typique : Machines/Équipements, Ordres de fabrication, Produits, Défauts/Rebuts, Interventions maintenance, Opérateurs. Chaque entité deviendra une table dans votre base no-code.
2. Définir les attributs essentiels de chaque entité
Pour « Machines » par exemple : ID_Machine (identifiant unique), Nom_Standard, Type, Ligne_Production, Date_Acquisition, Cadence_Nominale, Unité_Production.
3. Établir les relations entre entités
Une Machine produit plusieurs Ordres de fabrication. Un Ordre concerne un Produit. Une Machine génère des Interventions maintenance. Ces liens permettront des analyses croisées.
4. Standardiser les nomenclatures
C’est la clé de tout. Décidez maintenant des noms standards pour machines, produits, défauts, opérateurs. Créez des listes de référence (dropdown dans Airtable) pour empêcher les variations.
5. Définir vos indicateurs calculés
Quels KPI devront être calculés automatiquement ? TRS/OEE, taux de rebut, MTBF, temps de cycle moyen ? Intégrez-les dès la conception via des champs formule.
Erreur à éviter : Vouloir tout modéliser du premier coup. Commencez avec 3-5 entités principales. Vous étendrez progressivement. La perfection est l’ennemi du démarrage.
Conseil pratique : Dessinez votre modèle sur papier ou avec un outil comme Excalidraw avant de créer les tables. Validez-le avec les utilisateurs finaux : est-ce qu’il reflète leur réalité terrain ?
Résultat attendu : Un schéma de données validé avec 3-5 tables principales, leurs champs, et les relations entre elles. Ce modèle servira de blueprint pour votre base no-code.
Étape 3 : Nettoyer et préparer vos données historiques
Objectif : Transformer vos données Excel brutes en données propres, cohérentes, prêtes à l’import dans votre nouvelle structure.
Actions concrètes :
1. Standardisation des identifiants
Remplacez toutes les variations (« Presse 1 », « P1 », « Presse_01 ») par un identifiant unique standard. Utilisez la fonction Rechercher-Remplacer d’Excel de façon systématique.
2. Uniformisation des formats
Dates : format ISO 8601 (AAAA-MM-JJ). Nombres : séparateur décimal cohérent. Pourcentages : tout en décimal (0,032) ou tout en % (3,2%) mais jamais mixte. Heures : format 24h standard.
3. Traitement des valeurs manquantes
Ne laissez JAMAIS des cellules vides. Options : 0 pour valeurs numériques mesurées, « N/A » pour données non collectées, ou supprimer la ligne si trop de champs manquants. Documentez votre choix.
4. Détection et correction des outliers
OEE à 150% ? Temps de cycle négatif ? Identifiez les valeurs aberrantes (filtre automatique Excel, graphiques). Corrigez si erreur de saisie, supprimez si donnée corrompue.
5. Dédoublonnage
Supprimez les lignes dupliquées en utilisant « Supprimer les doublons » dans Excel après avoir trié vos données. Attention : vérifiez qu’il s’agit vraiment de doublons et pas de deux événements légitimes.
6. Enrichissement avec métadonnées
Ajoutez des colonnes contextuelles si manquantes : Source_Donnée (nom du fichier d’origine), Date_Import, Validé_Par. Ces métadonnées seront précieuses pour la traçabilité.
Erreur à éviter : Nettoyer directement dans votre fichier unique et écraser l’original. Faites TOUJOURS une copie avant toute modification. Gardez l’historique des transformations dans un fichier « Journal_Nettoyage.txt ».
Conseil pratique : Pour les gros volumes (>10 000 lignes), utilisez Power Query dans Excel ou un script Python simple. N8n propose aussi des nœuds de transformation de données très visuels, sans code.
Résultat attendu : Des fichiers CSV propres, standardisés, validés, prêts à l’import. Le taux de données exploitables devrait passer de 60-70% à 95%+ après ce nettoyage.
Étape 4 : Centraliser dans un outil no-code structuré
Objectif : Créer votre base de données centralisée dans un outil no-code et y importer vos données nettoyées.
Actions concrètes :
1. Choisir votre plateforme no-code
Pour les données industrielles, Airtable est souvent le meilleur choix : interface intuitive, formules puissantes, API complète, intégrations nombreuses. Alternative open-source : Baserow (hébergeable sur vos serveurs).
2. Créer votre structure de base
Dans Airtable, créez une « Base » pour votre production. Ajoutez une table par entité (Machines, Ordres, Produits). Configurez les champs selon votre modèle défini à l’étape 2.
3. Configurer les types de champs appropriés
- Single Select pour catégories fixes (Type_Machine: « Presse », « Tour », « Fraiseuse »)
- Number avec décimales pour mesures (Cadence, Taux_Rebut)
- Date avec heure pour horodatage
- Link to another record pour relations entre tables
- Formula pour calculs automatiques (TRS = Disponibilité × Performance × Qualité)
4. Importer vos données nettoyées
Utilisez la fonction d’import CSV d’Airtable. Mappez les colonnes de votre CSV vers les champs de votre table. Vérifiez la prévisualisation avant validation. Importez par lots si gros volumes.
5. Établir les liens entre tables
Connectez vos enregistrements : associez chaque Ordre de fabrication à sa Machine, à son Produit. Ces relations permettront des vues croisées et des analyses.
6. Configurer les vues métier
Créez des vues filtrées pour chaque utilisateur : « Maintenance » voit seulement les machines avec alertes, « Production » voit les ordres en cours, « Direction » voit le dashboard synthétique.
7. Définir les droits d’accès
Qui peut consulter ? Modifier ? Supprimer ? Airtable propose des permissions par table et par vue. Minimisez les accès en écriture pour préserver la qualité de données.
Erreur à éviter : Importer des données non nettoyées en pensant « on nettoiera après ». Non. Le nettoyage POST-import est 10 fois plus difficile. Faites-le avant.
Conseil pratique : Commencez avec UN mois de données historiques pour valider votre structure. Une fois que tout fonctionne, importez le reste de l’historique.
Résultat attendu : Une base Airtable opérationnelle avec vos données structurées, accessibles en temps réel par vos équipes, avec vues personnalisées par rôle.
Étape 5 : Automatiser l’alimentation continue des données
Objectif : Remplacer la saisie manuelle dans Excel par des flux automatisés qui alimentent votre base no-code en temps réel ou quasi-réel.
Actions concrètes :
1. Identifier les points de saisie actuels
Où naissent les données ? Saisie manuelle sur PC ? Notes papier retranscrites ? Export d’une machine ? Lecture de capteurs ? Chaque point est un candidat à l’automatisation.
2. Connecter les sources automatisables via n8n
N8n est un outil d’automatisation no-code open-source parfait pour l’industrie. Créez des workflows :
- Email → Airtable : Un export production arrive par email quotidiennement ? N8n l’extrait et l’envoie vers Airtable.
- Google Sheets → Airtable : Si certains utilisent encore Sheets pour saisie, synchronisation automatique toutes les heures.
- API machine → Airtable : Machines modernes avec API ? Récupération directe des données de production.
3. Mettre en place des formulaires de saisie structurée
Pour les données nécessitant saisie humaine (incidents, observations), remplacez Excel par des formulaires Airtable. Les opérateurs remplissent sur tablette/smartphone, les données arrivent directement structurées.
4. Configurer des validations automatiques
Dans n8n, ajoutez des nœuds de validation : « Si Taux_Rebut > 10%, envoyer alerte Slack au responsable qualité ». « Si Temps_Cycle > Cadence_Nominale × 1.5, marquer comme anomalie. »
5. Automatiser le nettoyage à la source
Les workflows n8n peuvent nettoyer les données à la volée : standardiser les noms de machines, convertir les formats, supprimer les doublons AVANT l’insertion dans Airtable.
6. Programmer des synchronisations régulières
Pour sources non connectables en temps réel, programmez des imports automatiques : tous les jours à 6h, n8n récupère le fichier du serveur, le nettoie, l’importe.
Erreur à éviter : Vouloir automatiser tout immédiatement. Automatisez flux par flux, en validant chacun. Priorisez les flux à haute fréquence et haute valeur (données production quotidiennes vs rapports mensuels).
Conseil pratique : Commencez par UN workflow simple qui génère de la valeur visible rapidement. Succès = adhésion des équipes = facilite l’extension.
Résultat attendu : 60-80% de vos données de production alimentent automatiquement votre base no-code. La saisie manuelle se limite aux cas particuliers et observations qualitatives. Vos données sont à jour en continu.
Les erreurs courantes à éviter
Erreur #1 : Vouloir la perfection immédiate
Le piège : Concevoir un modèle de données ultra-complet qui couvre 100% des cas d’usage imaginables, avec 15 tables et 200 champs. Résultat : 6 mois de conception, épuisement des équipes, projet abandonné avant le premier import.
Ce qu’il faut faire : Démarrez avec le Minimum Viable Data Model. 3-5 tables, 8-12 champs par table, les données les PLUS critiques. Mise en prod en 4-6 semaines. Extension progressive ensuite.
Règle d’or : « Done is better than perfect ». Mieux vaut une base simple qui fonctionne qu’une base parfaite qui n’existe que sur papier.
Erreur #2 : Négliger la conduite du changement
Le piège : Créer la plus belle base de données no-code du monde, l’annoncer par email, et constater 3 semaines plus tard que personne ne l’utilise. Les équipes continuent leurs Excel « parce que c’est plus rapide ».
Ce qu’il faut faire :
- Impliquer les utilisateurs dès l’étape 1 : ils co-conçoivent le modèle, ils s’approprient l’outil.
- Former en pratique : pas de PowerPoint théorique, mais des sessions terrain sur CAS RÉELS.
- Créer des quick-wins visibles : un dashboard qui affiche le TRS en temps réel impressionne plus qu’un long discours.
- Désactiver progressivement les anciens fichiers Excel : rendre l’ancien système moins pratique que le nouveau.
Conseil RNA Solutions : Prévoyez 30% de votre temps projet sur l’accompagnement humain. La technique n’est que 70% du succès.
Erreur #3 : Ignorer la gouvernance des données
Le piège : Base no-code créée, tout le monde a tous les droits, chacun modifie ce qu’il veut. En 3 mois, retour au chaos : doublons, incohérences, suppressions accidentelles.
Ce qu’il faut faire :
- Nommer un data owner : une personne responsable de la qualité et de la cohérence des données.
- Définir les rôles et permissions : consultation large, modification restreinte, suppression ultra-restreinte.
- Établir des règles de nommage : documentation claire sur comment nommer une machine, un produit, un défaut.
- Programmer des audits qualité mensuels : vérifier taux de remplissage, cohérence, doublons.
Outil pratique : Créez un « Guide des bonnes pratiques données » d’une page A4, affiché dans l’atelier et disponible dans Airtable.
Erreur #4 : Sous-estimer les ressources nécessaires
Le piège : « On va faire ça en interne sur notre temps libre ». 6 mois plus tard, 10% du projet est fait, l’équipe est frustrée, la direction est déçue.
Ce qu’il faut faire : Budgétiser temps ET compétences.
Pour un projet type PME (3-5 tables, 12-24 mois d’historique, 3 workflows automatisés) :
- Temps interne : 15-20 jours répartis sur 3 mois (audit, validation modèle, nettoyage, formation)
- Accompagnement externe : 10-15 jours pour expertise technique no-code et automatisation
- Budget outils : 500-1500€/an (licences Airtable Pro, n8n hébergé si pas auto-hébergé)
Alternative : RNA Solutions propose des accompagnements structurés sur 4-8 semaines, du diagnostic gratuit initial jusqu’à la mise en production et formation des équipes.
Erreur #5 : Ne pas penser « évolutivité »
Le piège : Concevoir une structure figée qui répond aux besoins d’aujourd’hui mais sera obsolète dans 12 mois quand vous voudrez ajouter de nouveaux cas d’usage.
Ce qu’il faut faire :
- Choisir des outils avec API ouvertes : Airtable, Baserow ont des API complètes. Vous pourrez toujours connecter de nouveaux systèmes.
- Documenter votre modèle de données : dans 6 mois, quelqu’un (vous ?) devra le faire évoluer. La documentation accélère ce travail.
- Utiliser des identifiants uniques stables : ne jamais utiliser le nom d’une machine comme identifiant (il peut changer), mais un ID_Machine permanent.
- Prévoir des champs « metadata » extensibles : une colonne « Notes » ou « Tags » permet d’ajouter des infos sans modifier la structure.
Vision RNA Solutions : Votre infrastructure de données doit vivre et évoluer 5-10 ans. Pensez-la comme une fondation sur laquelle vous bâtirez progressivement.
Outils et ressources pour structurer vos données
Outils no-code de bases de données recommandés
Airtable | Interface type spreadsheet + base de données | 15€-20€/utilisateur/mois (plan Pro)
- Points forts : Interface intuitive, formules puissantes, vues multiples (Grid, Kanban, Calendar, Gallery), API excellente, marketplace d’intégrations riche
- Points faibles : Hébergement USA uniquement (cloud), coûts qui augmentent avec le nombre d’utilisateurs
- Idéal pour : PME 10-100 salariés cherchant rapidité de déploiement et facilité d’usage
Baserow | Alternative open-source à Airtable | Gratuit (auto-hébergé) ou 15€/utilisateur/mois (cloud)
- Points forts : Open-source, hébergeable sur vos serveurs (souveraineté données), pas de limite d’enregistrements, API complète
- Points faibles : Interface moins raffinée qu’Airtable, moins d’intégrations natives
- Idéal pour : Entreprises avec contraintes RGPD fortes ou équipes IT qui peuvent auto-héberger
Notion | Base de données + documentation | 10€/utilisateur/mois
- Points forts : Combine base de données ET wiki/documentation, excellent pour projets avec beaucoup de contexte textuel
- Points faibles : Moins performant sur gros volumes (>10k enregistrements), formules moins puissantes qu’Airtable
- Idéal pour : Projets mixtes données + documentation (ex: données production + procédures)
Outils d’automatisation et intégration
N8n | Automatisation workflows open-source | Gratuit (auto-hébergé) ou 20€/mois (cloud)
- Connecteur natif Airtable, Google Sheets, APIs diverses
- Interface visuelle de conception de workflows
- Comparatif détaillé n8n vs Make
Make (ex-Integromat) | Automatisation no-code cloud | 9€-29€/mois selon volume
- Plus d’intégrations natives que n8n (1000+)
- Interface très visuelle et intuitive
- Meilleures performances sur workflows complexes
Zapier | Leader du marché automatisation | 20€-50€/mois
- Le plus d’intégrations (5000+)
- Très simple pour automatisations basiques
- Plus cher et moins flexible que n8n/Make pour cas industriels
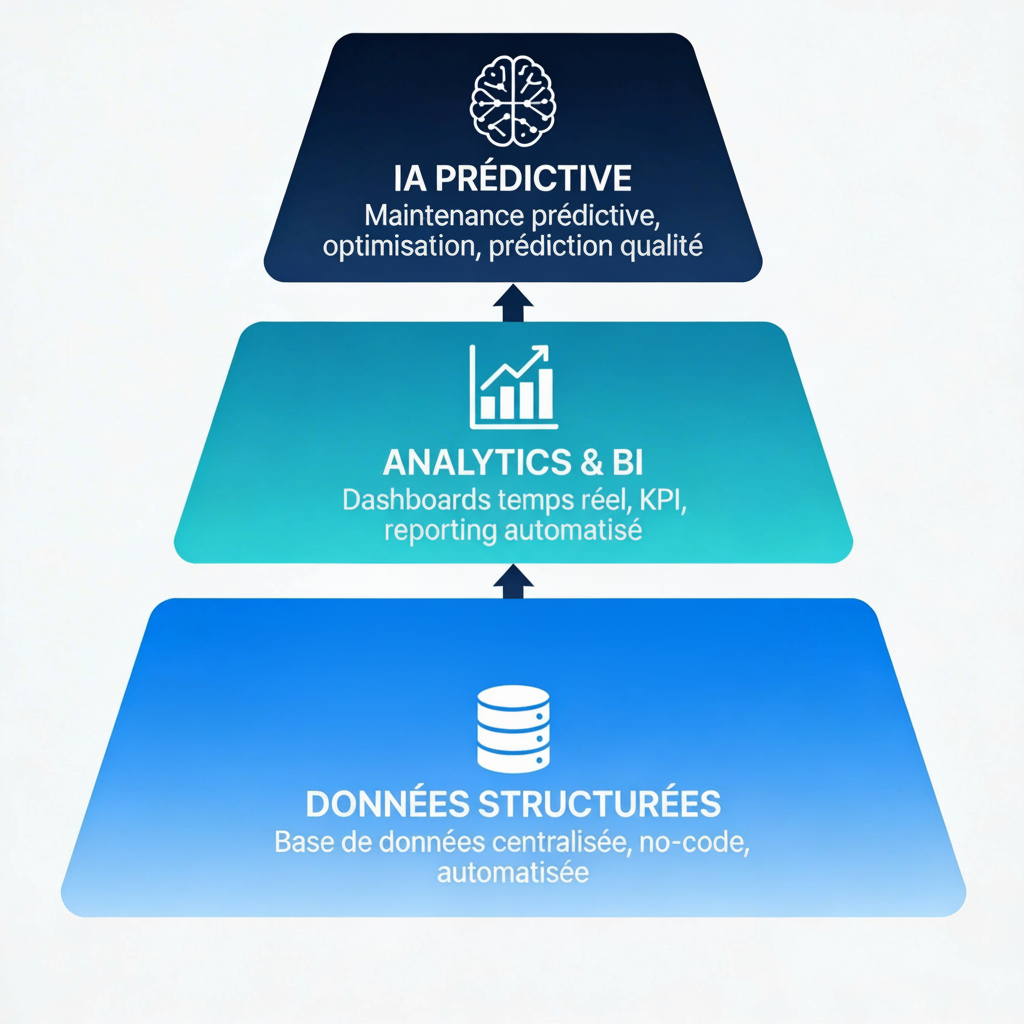
Préparer vos cas d’usage IA : les fondations sont posées
De la structure de données aux algorithmes
Une fois vos données structurées, centralisées et automatisées, vous disposez du carburant nécessaire pour alimenter l’IA. Les cas d’usage deviennent techniquement possibles :
Maintenance prédictive
Avec historique propre d’arrêts machines, durées d’intervention, pièces remplacées, l’IA peut détecter les patterns annonçant une panne. Anticipation possible 1-2 semaines avant défaillance.
Optimisation de planification
Données de temps de cycle, taux de rebut, disponibilité machines permettent à l’IA de proposer des ordres de fabrication optimisés : moins d’en-cours, meilleure utilisation capacités.
Prédiction qualité
En croisant paramètres process (température, vitesse, pression) avec résultats contrôle qualité, l’IA identifie les dérives AVANT production de rebuts. Ajustement proactif des réglages.
Analyse des causes racines
L’IA peut analyser automatiquement des milliers d’arrêts et identifier les corrélations : « Ligne 2 s’arrête 3× plus souvent les lundis matin quand l’équipe A démarre » → investigation ciblée.
Les prérequis data pour l’IA manufacturière
Volume : Minimum 6-12 mois d’historique pour cas d’usage prédictifs. Idéalement 24-36 mois pour robustesse.
Fréquence : Plus la granularité est fine, meilleure est la prédiction. Données horaires > quotidiennes > hebdomadaires.
Complétude : Visez 95%+ de taux de remplissage. L’IA tolère quelques trous, pas des gouffres.
Cohérence : Les formats, unités, nomenclatures doivent être constants sur TOUTE la période historique.
Contexte : Les données brutes (mesures) + le contexte métier (équipe, produit, conditions) = richesse pour l’IA.
Votre base no-code structurée répond à tous ces critères. Vous êtes prêt pour la phase suivante.
Les outils IA no-code compatibles avec votre infrastructure
Latenode : Plateforme no-code qui intègre directement Claude, GPT, Gemini dans des workflows connectés à Airtable. Permet de créer des analyses prédictives simples sans data scientist.
BigML : Outil no-code d’analyse prédictive et machine learning. Import direct depuis Airtable, création de modèles par interface graphique.
Obviously AI : No-code ML spécialisé prédiction. Connecte votre base Airtable, vous choisissez ce que vous voulez prédire, l’outil entraîne le modèle automatiquement.
Pour cas d’usage plus complexes : RNA Solutions développe des solutions sur-mesure combinant vos données structurées, algorithmes d’IA spécialisés manufacturiers, et dashboards de pilotage dans Power BI ou Grafana.
Conclusion : Votre feuille de route vers l’IA commence aujourd’hui
Structurer vos données de production n’est pas une contrainte technique, c’est un investissement stratégique. Sans cette fondation, votre usine reste pilotée « au feeling », vos décisions se basent sur des intuitions, et l’IA reste un rêve inaccessible.
Les 5 étapes présentées dans ce guide vous donnent une méthode éprouvée pour passer du chaos Excel à une infrastructure no-code moderne :
- Auditer vos sources actuelles pour savoir d’où vous partez
- Modéliser la structure cible qui supportera vos besoins futurs
- Nettoyer vos données historiques pour les rendre exploitables
- Centraliser dans un outil no-code accessible et collaboratif
- Automatiser l’alimentation continue pour rester à jour en permanence
La bonne nouvelle ? Vous n’avez pas besoin de tout faire en un jour. Commencez petit : une machine, un mois de données, un workflow automatisé. Les premiers résultats visibles en 4-6 semaines créent la dynamique. L’extension se fait progressivement, flux par flux, cas d’usage par cas d’usage.
Le coût ? Bien inférieur à ce que vous imaginez. Entre 3000€ et 8000€ pour un projet complet PME (outils + accompagnement), amorti en 6-12 mois par les gains de temps et de fiabilité. Les aides publiques 2026 pour transformation digitale couvrent 30-50% de l’investissement dans le Grand Est.
Le ROI ? Mesurable dès les premières semaines : temps gagné sur consolidation Excel, décisions plus rapides basées sur chiffres fiables, moins d’erreurs de saisie, meilleure réactivité aux dérives production.
Structurez vos données de production en 8 semaines
RNA Solutions vous accompagne de l’audit initial à la mise en production :
- ✓ Audit gratuit de vos fichiers Excel et flux de données
- ✓ Modèle no-code (Airtable/Baserow) configuré avec vos équipes
- ✓ Automatisation des flux de saisie (n8n/Make)
- ✓ Dashboards TRS, qualité et alertes en temps réel
- ✓ Formation terrain de vos opérateurs et chefs de ligne
Réserver mon diagnostic gratuit (30 min) →
Sans engagement. Éligible aides BPI France & Région Grand Est.
FAQ
Combien de temps faut-il pour structurer les données d’une PME industrielle ?
Pour une PME typique (10-100 salariés, 2-5 lignes de production), comptez 8 à 12 semaines de la première réunion à la mise en production. Cela inclut l’audit (1-2 semaines), la modélisation (1 semaine), le nettoyage de 12-24 mois d’historique (2-3 semaines), la configuration de la base no-code (1 semaine), l’automatisation des flux (2-3 semaines) et la formation des équipes (1 semaine). Le temps se réduit à 4-6 semaines si vous ne structurez qu’une ligne de production en pilote.
Faut-il des compétences techniques pour utiliser des outils no-code ?
Non. C’est justement l’intérêt du no-code. Si vous savez utiliser Excel (filtres, tableaux, formules de base), vous saurez utiliser Airtable. Pour n8n, l’interface drag-and-drop est très visuelle : vous connectez des blocs par des flèches. La formation nécessaire est de 2-3 heures pour utilisateurs finaux, 1-2 jours pour administrateurs. RNA Solutions forme vos équipes directement dans votre usine sur vos cas réels.
Peut-on garder Excel en parallèle pendant la transition ?
Oui, c’est même recommandé pendant 4-8 semaines. Fonctionnez en double saisie temporaire : les anciennes feuilles Excel continuent + la nouvelle base no-code démarre. Cela sécurise la transition et permet de vérifier la cohérence des données. Une fois la nouvelle base validée, désactivez progressivement les anciens fichiers Excel. Conservez-les en archive, mais bloquez les modifications.
Quels sont les coûts d’outils pour une PME de 30 personnes ?
Budget annuel type : Airtable Pro (4-8 utilisateurs × 20€/mois) = 960-1920€/an. N8n cloud (workflows illimités) = 240€/an OU n8n auto-hébergé = 0€ (si vous avez serveur). Total : 1200-2160€/an pour outils, soit 100-180€/mois. Alternative moins chère : Baserow open-source auto-hébergé (0€) + n8n auto-hébergé (0€) = coût quasi-nul si ressources IT internes. Pour comparaison, un MES traditionnel coûte 30 000 à 150 000€.
Nos données sont confidentielles, peut-on héberger en France ?
Oui. Airtable est hébergé aux USA (cloud uniquement), mais propose contrat DPA conforme RGPD. Pour souveraineté totale, utilisez Baserow (open-source, auto-hébergeable sur vos serveurs ou chez un hébergeur français type OVH/Scaleway) + n8n auto-hébergé. Vous gardez 100% contrôle de vos données. RNA Solutions peut configurer et maintenir cette infrastructure pour vous.
Que faire si on n’a pas 12 mois d’historique de données ?
Commencez avec ce que vous avez, même 3 mois suffisent pour structurer. L’important est de mettre en place la structure ET l’automatisation maintenant. L’historique se construit progressivement. En 6-12 mois d’alimentation automatique, vous aurez la profondeur nécessaire pour cas d’usage IA. Mieux vaut démarrer aujourd’hui avec peu de données que d’attendre 12 mois en continuant Excel chaotique.
Comment convaincre la direction d’investir dans la structuration des données ?
Présentez 3 arguments concrets : 1) Temps gagné mesurable : « Actuellement, 12h/semaine perdues en consolidation Excel = 600h/an = 18 000€/an de temps gaspillé ». 2) Risque décisionnel : « 62% de nos données sont incohérentes, nos décisions de planification se basent sur des chiffres faux ». 3) Blocage stratégique : « Impossible de faire IA/prédictif sans données structurées, nos concurrents avancent pendant qu’on stagne ». Proposez un pilote sur UNE ligne, 6 semaines, 5000€ : résultats tangibles convaincront pour extension.